Where is my solitaire?
|
As
a non-native English user (rather a writer than a speaker), I may be
more sensitive to certain features of this thoroughly polished language
than native users. While the German language tends to create monsters
by joining words together, the English language more elegantly allows
the grouping of words into convenient phrases. Sometimes, these words
seem to stick together like glue.
|
For
example, I just found out - with the help of google of course - that
this search engine finds the phrase "stick together like glue" 42.100
times in the world-wide web. By starting to write the phrase, several
other continuations are proposed, among them also the phrase "stick
together like birds of a feather" (6.540 hits). How to judge the number
of these hits?
|
I
came to the idea to perform for a phrase two different searches, one
without and the other with the quotation marks (the quotation marks
limit the search to the strict word order). By this strategy, you
sometimes get quite surprising results. Leaving out the quotation marks
from stick together like glue increases the number of hits to
impressive 23.300.000, dwarfing the number of true hits. Also the
second phrase (citing the birds) goes up to more than 3.000.000 hits.
|
The
reason is obvious: many more documents exist with the words stick,
together, like, & glue, without being close to each
other.
But try by yourself: Just for your curiosity, google for "birds of a
feather", and then repeat the search without the quotation marks. You
will be surprised. Both searches yield about the same high number of
hits: 12.300.000 with, 12.600.000 without quotation marks.
|
An even more surprising result is obtained with the unremarkable phrase "preaching to the choir":
google's search engine returns 2.700.000 hits already with quotation
marks; strangely enough, this number goes DOWN to a mere 500.000 by
leaving them out. How can that be? Shouldn't any document with the
words A, B, C, & D in exactly that order also be found if the words were anywhere in the document?
|
If
we would
have searched a standard text corpus, such a result would be difficult
to explain. However, google searches are different: they apply to an
ill-defined, pre-searched corpus resulting from countless web-crawling
robots with secret priorities. We cannot be sure that searches between
quotation marks graze on the same corpus as searches without them.
|
Intrigued
by several additional results, I spent some evenings by putting google
to the statistical test. The result was perplexing (see the figure
above). I limited my search to phrases comprising 3-6 words, and I
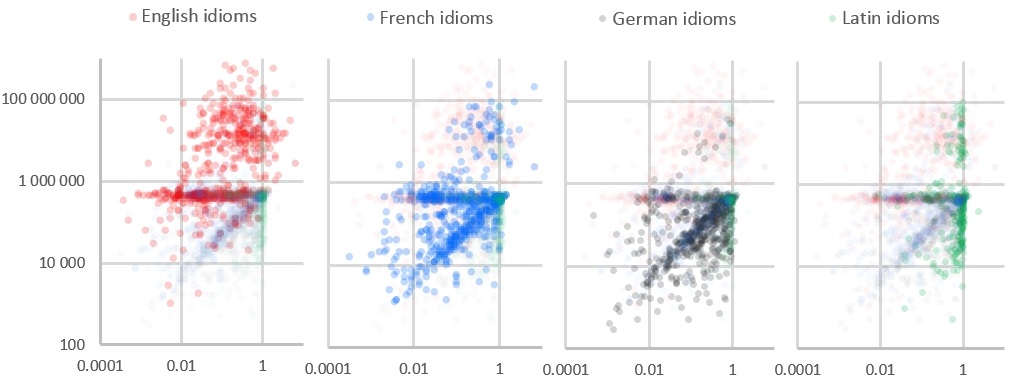
differentiated common phrases (1.004) from technical ones (153; not shown in the figure). Examples
for technical phrases would be "speed of light" and "thin layer chromatography".
|
In addition to the one
mentioned, I discovered 3 more phrases with at least 3 times more hits
with than without quotation marks: finger on the pulse; at the same time; and latter day saints
(red points with x>3 in the upper cloud). The
reason is unclear to me. These phrases do not appear to have anything
in common. The vast majority obeys the contrary rule: fewer hits with
quotation marks (x<1).
|
Even more intriguing are
regularities that become apparent to the free eye after plotting a
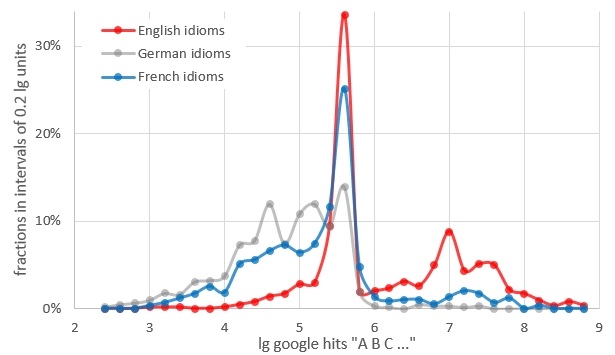
sufficiently large number of hits. Obviously, English
phrases come in 2 varieties: the first one flocks around 400-500 000
hits (calling to mind the milky way), while the second one scatters
between 3 and 300 millions (rather reminiscent of a globular cluster).
Until now, I
didn't find out what these 2 crowds have in common. Both comprise
common phrases and technical ones. 'Strange results' with more hits
with quotation marks than without them are only seen in the higher
frequency hord.
|
Musing about these observations I remembered my collection of German idioms started more than 20 years ago. From
more than 2.000 entries, I extracted 1.050 phrases with 3-7 words. This
was more difficult than in the English case, since the detailed wording
is in German more sensitive to grammar. I had to omit a large part
for that reason, but nevertheless ended up with an impressive crowd
(grey dots in the figure).
|
In general, I found
fewer German than English phrases on the internet (by about a factor 20). Nevertheless, several German idioms join their English
cousins in the frequency band from 400 to 500 thousand hits, and very
few even rocket up to the higher crowd; but the major part exhibits
lower frequencies. In this main fraction, a high number of hits without
quotation marks seems to be of negative influence on phrase frequency.
|
Next I tried to remember the French of my earlier days (blue symbols in the
figure).
French idioms (999 common, 40 technical ones - not shown) were about 10 times less frequent
on the internet than English ones.
They also split in 2 categories, like the English ones do, but
there was an additional fraction at lower frequencies, as in the
case of German. In fact, from a statistical point of view, French seems
to occupy a position between English and German (see the figure
below).
|
Finally,
I surprised myself by discovering the treasure of Latin sayings
slumbering in the depths of my unconscious (I enjoyed 7 years...). Up
to now, I managed to come up with 307 of them (and still counting).
These sterile
relicts of an ancient speech have real strange statistics (green dots
in the figure above). They mostly obey the rule x = 1; that means
they always come in the same combinations, with very low fluctuation.
Apparently, all that remains from a dead language ARE the idioms - like
the bones from a living creature.
|
You may think now: what
a lazy scientist. Doesn't he have better to do than to fool around with
nonsense like this? And you would be right: I should play solitaire as
all the others in those magic extra-minutes after work, but - alas -
after my recent computer breakdown caused by a virus my instrument was
set up without solitaire...
|
2/17 < MB
(4/17) > 4/17
|
Ps:
I also found out that google search results are rather volatile. From
one day to another, some hit numbers may change by more than a factor
10 (this is
more than should be expected as a consequence of the steady increase in
the sheer volume of the total text corpus in the internet). So, don't
be surprised of you cannot reproduce exactly the hits presented here.
|
Berger ML
(2019) On the 'stickiness' of words. A comparative language study
screening the internet for English, German, French and Latin phrases. J Quantitative Linguistics 26: 81-94
|
Caliskan A,
Bryson JJ, Narayanan A (2017) Semantics derived automatically from
language corpora contain human-like biases. Science 356: 183-86
|
Nelson MJ,
El Karoui I, Giber K, Yang X, Cohen L, Koopman H, Cash SS, Naccache L,
Hale JT, Pallier C, Dehaene S (2017) Neurophysiological dynamics of
phrase-structure building during sentence processing. 10.1073/pnas.1701590114
|